Why use version control?
Part of an occasional series of posts discussing the sometimes mysterious intersection of sound and music research with software development
Version control – also called source control or revision control – is a big and complicated subject, but the point of it is easily enough explained:
- A version control system remembers the history of your files. If you stuff something up, you can get an earlier version back again.
- A version control system helps you share changes. It makes things easier to manage if several of you are working together, or if you are working in more than one location.
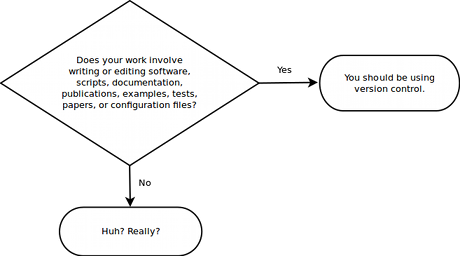
Here is a simple decision diagram that will help you decide whether you should be using version control for your research software and related files.
What does a version control system consist of?
It depends what kind it is.
There are two quite different kinds in popular use: distributed and centralised.
With either kind, you have a working copy, which is a folder with your project's files in it on your own hard drive, and you have a repository, which is a record of the entire history of your project. When you have changed something in the working copy, you then commit it to the repository; you can then grab any older version from the repository if you find you need it.
The two kinds differ in where the repository lives:
- A distributed version control system is a program that stows the entire history of your project files into a special hidden folder inside the working copy on your hard drive. Every commit you make gets added to the history in that hidden folder. (The history is compressed, so it doesn't take as much space as you might imagine.)
You can then transfer your project history between different copies of the repository; each copy contains the entire history (this is what makes it a distributed system) and the software knows how to keep the copies in sync even after they have been modified independently. It's common to keep a “master copy” on a server elsewhere, which you and your collaborators can use to keep up with each other's work, or which you can use to make your work public, or simply use as a private backup. But you don't have to have a separate server in order to keep track of your changes: just your working folder and the version control software which manages that hidden folder of history inside it.
Popular distributed version control systems include git and Mercurial.
- A centralised version control system is arranged a bit differently. Centralised systems use a central server, a bit like a database, which stores your files' history and controls access to your files. This is kept separately from your working copy. Typically it lives on a dedicated server host, like the “master copy” concept for a distributed system, although you can just nominate another folder on your hard drive to contain your repository if you like.
With a centralised system, your working copy only stores the current versions of your project's files, and whatever changes you're working on now. The only copy of the full history is in the repository. So, when you commit a set of changes, they go directly to the central repository where your collaborators get to see them immediately – in contrast to the situation with a distributed system where the changes go into your local repository first and only get shared when you decide to share them.
The best known centralised version control system is probably Subversion, although large companies often use commercial products such as ClearCase or Perforce.
Which kind is better? That depends; they both have legitimate advantages and disadvantages. The only certainty is that either of them is better than no version control at all. We'll cover the reasons to pick a particular system later on.
Isn't this too much trouble for my crappy experimental program?
No. Setting up and using version control has possibly the best payoff, in terms of improving your research effectiveness and general happiness straight away, of any change you could make in your working practices.
You're working on a handful of Python or Matlab files. You make a few changes, and then you want to try something you're not quite confident about yet, so you save a copy in another folder just in case.
Then you want to try out the program with more data on a bigger server, and you make a few changes there to get it working properly. Then you try out something else in the copy on your laptop.
Now you have three or four copies, all slightly different, and you have some results generated from all of them, and you include some of it in a paper.
Then someone asks for the same results based on a new data file. You have to go off and remind yourself which version you used, find out whether you still have it at all or whether you've changed it again since, check whether it really has the vital changes you thought you'd included but that might have been only on that other machine, and so on.
By now you have already wasted more time than it would have taken to get version control working well for you, and you've only just begun. (Eventually you end up with a situation like this and things really start to get nasty.)
Version control reassures you and the people you collaborate with, gives you the confidence to carry out more ambitious experimental work, and makes your everyday working processes simpler and more satisfying.
